
こんにちは
島村竜一です。
近年、AIチャットボットの導入があちこちでドンドン進んでいっています。
人手不足ということでAIチャットボットの導入がかなり期待されています。
とはいえ。。。。
多くの企業がその導入に躊躇している現状があります。
やはりはやっているAIは海外にデータを送られてしまうのを心配しているようです。
そんななか注目を集めつつあるのがローカルLMMになります。
ローカルLMMを使うと海外にデータが送られず安心して使うことができます。
前回このよう記事を書きました。
https://goodsystem.jp/ai/local-ai-llama-3-elyza-jp-8b-benefits-and-cons.html
今回はローカルLMMの実装方法について解説をさせていただきます。
ローカルLMMの実装方法準備編
1
こちらからローカルLMMをダウンロードします。
https://huggingface.co/elyza/Llama-3-ELYZA-JP-8B-GGUF/tree/main
Llama-3-ELYZA-JP-8B-q4_k_m.ggufの箇所をクリックしてダウンロードします。
注意 容量がありますのでダウンロードに時間がかかりますのでコーヒーでも飲んでまっていてください。
2
Python実行環境を用意します。
Pythonをインストールしておいてください。
Pythonは下記のサイトからダウンロードできます。
バージョンは最新版で大丈夫です。
https://www.python.org/
3.
VisualStudioをダウンロードします。
https://code.visualstudio.com/
ローカルLMMの実装方法実行編
では実際にPythonで動かしてみましょう。
ローカルLMMを実行するためのライブラリーをインストールします。
pip install llama-cpp-python今回のプログラムでは下記のライブラリーも必要ですのでpipでインストールしておきましょう。
pip install streamlit==1.39.0
pip install streamlit-feedback==0.1.3
pip install langchain-community==0.3.2
実際に動くプログラムはこちらです。
# 各ライブラリのインポート
import streamlit as st
from langchain_community.llms import LlamaCpp
# モデルの準備、プロンプト編集する部分
def use_model(text):
#下記のパスをダウンロードし保存したLlama-3-ELYZA-JP-8B-q4_k_m.ggufのパスに変えること
MODEL_NAME = "C:/999-dev/2025_ai_chat/model/Llama-3-ELYZA-JP-8B-q4_k_m.gguf"
# モデルの準備
llm = LlamaCpp(
model_path=MODEL_NAME,
)
# プロンプト編集部分
prompt = "あなたは誠実で優秀な日本人のアシスタントです。特に指示が無い場合は、常に日本語で回答してください。{}。".format(text)
# モデルの実行
return llm.invoke(prompt)
def use_model(text):
MODEL_NAME = "C:/999-dev/2025_ai_chat/model/Llama-3-ELYZA-JP-8B-q4_k_m.gguf"
print(f"Using model from: {MODEL_NAME}") # パスを表示
llm = LlamaCpp(
model_path=MODEL_NAME,
)
prompt = "あなたは誠実で優秀な日本人のアシスタントです。特に指示が無い場合は、常に日本語で回答してください。{}。".format(text)
return llm.invoke(prompt)
# UI(チャットのやり取りの部分)
def main():
# タイトル
st.title("LLMアプリ")
# 入力フォームと送信ボタンのUI
st.chat_message("assistant").markdown("何か聞きたいことはありませんか?")
text = st.chat_input("ここにメッセージを入力してください")
# チャットのUI
if text:
st.chat_message("user").markdown(text)
st.chat_message("assistant").markdown(use_model(text))
if __name__ == "__main__":
#test_text = "こんにちは、テストメッセージです。"
#use_model(test_text)
main()
上記のプログラムは下記のコマンドで実行することができます。
streamlit run test_LlamaCpp.py
動かしてみるとこのような形になります。
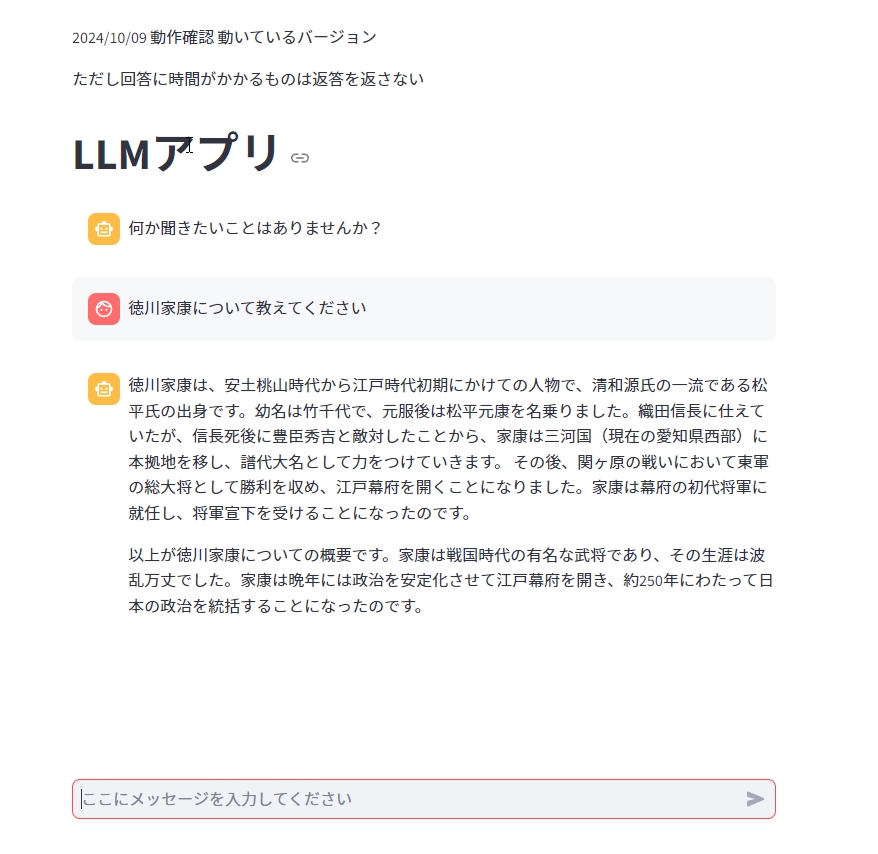
まとめローカルLMMを動かすだけなら簡単!
こんな感じでお手軽にローカルLMMを動かすことできます。
やってみるとひょうしぬけするほど簡単にローカルLMMを動かすことができます。
試してみるとなかなかおもしろくローカルLMMを動かすことができるのが感動です。
さて
人手不足がますます叫ばれる今の時代、どこでも仕事量がドンドン増えていっている状態です。
求人をかけてもなかなか人が集まらない。
いつまでたっても忙しいが解消されない。
今いる人がヘトヘトになってやめてします。
そんな悪循環が生じていませんか?
チャットボットを導入することにより社内の業務をすばやく的確にこなしていくことができます。
そんなとき安心安全なローカルAI(Llama-3-ELYZA-JP-8B)を検討してみてはいかがでしょうか?
下記のメルマガに登録していただけるとローカルAI(Llama-3-ELYZA-JP-8B)の情報やさまざまなAIの使い方などを解説しています。
ぜひメルマガ登録してみてくださいね。
ローカルAI(Llama-3-ELYZA-JP-8B)などAIの導入に関することのお問い合わせはこちらからお願いします。
次回の記事はローカルAIをカスタマイズするためにDifyサーバーについて解説をします。
それではここまで読んでくださってありがとうございました。
また次の記事でお逢いしましょう。
仕事の生産性をあげるためさまざまな方法を試しました。その結果UiPathにたどり着き現在UiPathを使った業務効率化の開発、講師の仕事をしています。
講師、開発などの相談はお問い合わせからお願いします。

