
はじめに
本記事は、2023年12月開催の「UiPath (produced with UiPath Friends) Advent Calendar 2023」の参加ブログです。
UiPath (produced with UiPath Friends) のカレンダー | Advent Calendar 2023 – Qiita
ぜひ他の記事も見てみてくださいね!
さて
ここのところ必死こいてUiPathのDocument Understandingを研究している島村竜一です。
いままで書いた記事について
Document Understandingはいろいろ動かしてみると本当に面白いです。
ぜひDocument Understandingについてまとめた記事も読んでくださいね。
Document Understandingにおいて処理を行うためには5段階の処理を行う必要があります。
1.タクソノミー
2.デジタル化
3.分類
4.抽出
5.エキスポート
になります。
今回は1.タクソノミーと2.デジタル化についてつまづきそうなところを解説しますね。
タクソノミーとは
タクソノミーでやること:
コンピューターにスキャンするファイルにおいてどういうデータをどういう型で取り込むかを定義します。
例
フィールド名
PesonName
種類
Name
フィールド名
siboudouki
種類
Name
フィールド名
birthday
種類
Date
UiPathでは「タクソノミーマネージャー」というツールを使ってどういうデータを取り込むべきかを
定義します。
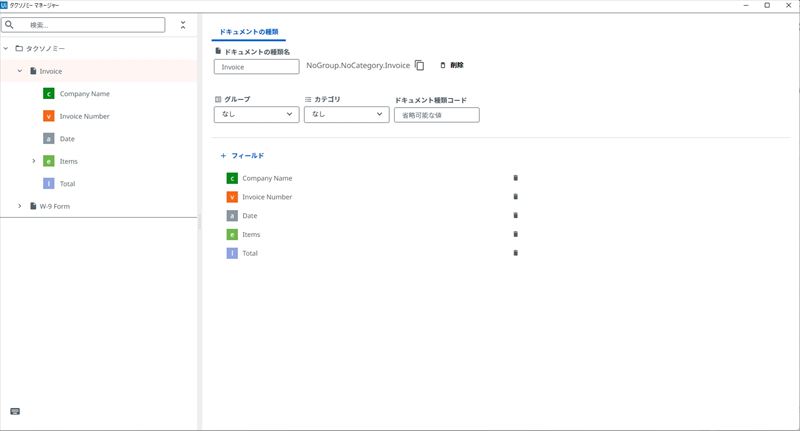
「タクソノミーマネージャー」で定義が終わった後は
タクソノミーを読み込みアクティビティを追加して先ほどのタクソノミーを読み込みます。
デジタル化とは
実際にコンピューターにスキャンするデータを読み込みます。
スキャンする時のOCRで注意することがあります。
実際に事例でご紹介します。
今回はこの履歴書を読み込むことにしました。

初期設定では
UiPath Document OCR
が選ばれています。
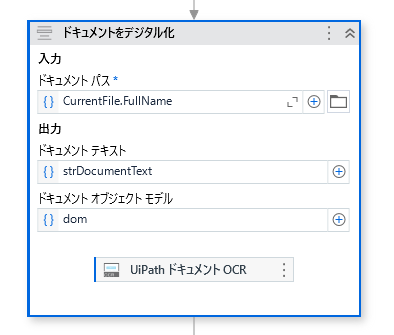
UiPath Document OCRだと日本語は文字化けしてしまいます。
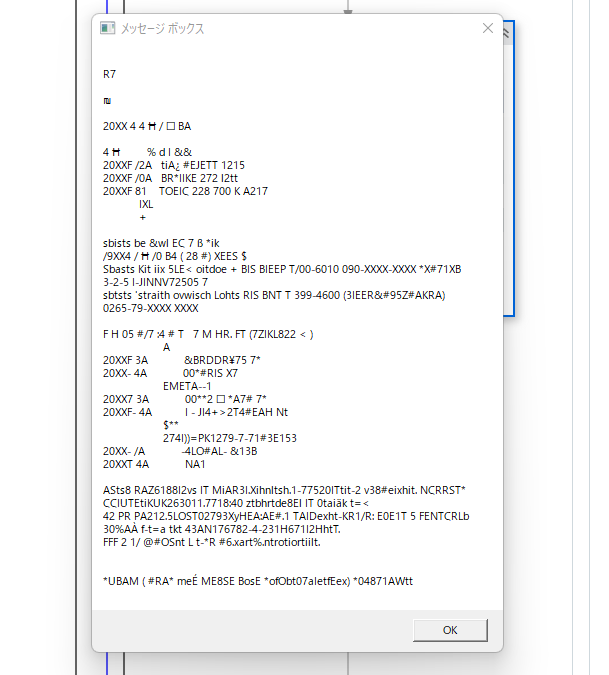
削除して
OCR – 中国語、日本語、韓国語
を設定するようにしてください。
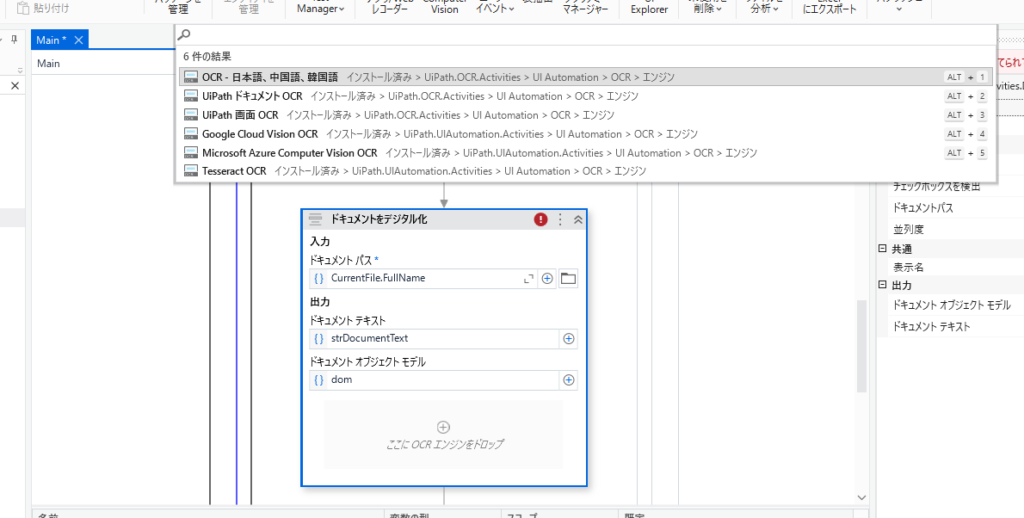
そうすると正しく日本語を読み込むことができます。
まとめ:データをただスキャンしただけでは意味がない。どの場所にどういったデータが入っているかが重要です。
OCRという技術がでてきたことによって紙のデータをコンピューターに取り込めるようになりました。
でもただ取り込めるだけではもちろんダメなんです。
例えば
履歴書を取り込んだ時に適切な言葉が入っているか?
年齢はいくつなのかを
後で適切に分類して取り出せるようにする必要があります。
「Document Understanding」を使うと書類の該当する場所に適切なデータを取り出して分類することができます。
これができるようになるとまさしく事務処理がまちがいなく進むはずですよね。
きっとUiPathの「Document Understanding」を使えばもっと仕事が楽になるはずです。
ではまた次のブログでお逢いしましょう。
仕事の生産性をあげるためさまざまな方法を試しました。その結果UiPathにたどり着き現在UiPathを使った業務効率化の開発、講師の仕事をしています。
講師、開発などの相談はお問い合わせからお願いします。
Warning: Undefined array key "legacy_landing_pages" in /home/miraijyuku/goodsystem.jp/public_html/wp-content/plugins/convertkit/vendor/convertkit/convertkit-wordpress-libraries/src/class-convertkit-resource-v4.php on line 664
Warning: foreach() argument must be of type array|object, null given in /home/miraijyuku/goodsystem.jp/public_html/wp-content/plugins/convertkit/vendor/convertkit/convertkit-wordpress-libraries/src/class-convertkit-resource-v4.php on line 664

